Metin, görsel, video, ses ve PDF — ilk kez tek bir vektör uzayında. Mart 2026'da yayınlanan model, AI altyapısının kurallarını yeniden yazıyor.
Bir metin sorgusuyla video içinde sahne aramak istediğinizde, şimdiye kadar önce o videoyu metne çevirmeniz gerekiyordu. Ayrı bir model, ayrı bir pipeline, ayrı bir maliyet kalemi. Google DeepMind'ın 10 Mart 2026'da public preview olarak yayınladığı Gemini Embedding 2, bu ara katmanları tek hamlede ortadan kaldıran ilk native multimodal embedding modeli.
Model adı "embedding" kelimesini taşıyor — ve bu, ChatGPT veya Gemini gibi üretken modellerden farklı bir kategori. Üretken modeller yeni içerik oluşturur; embedding modelleri ise mevcut verileri sayısal vektörlere dönüştürerek anlamlandırır, sınıflandırır ve aranabilir kılar.
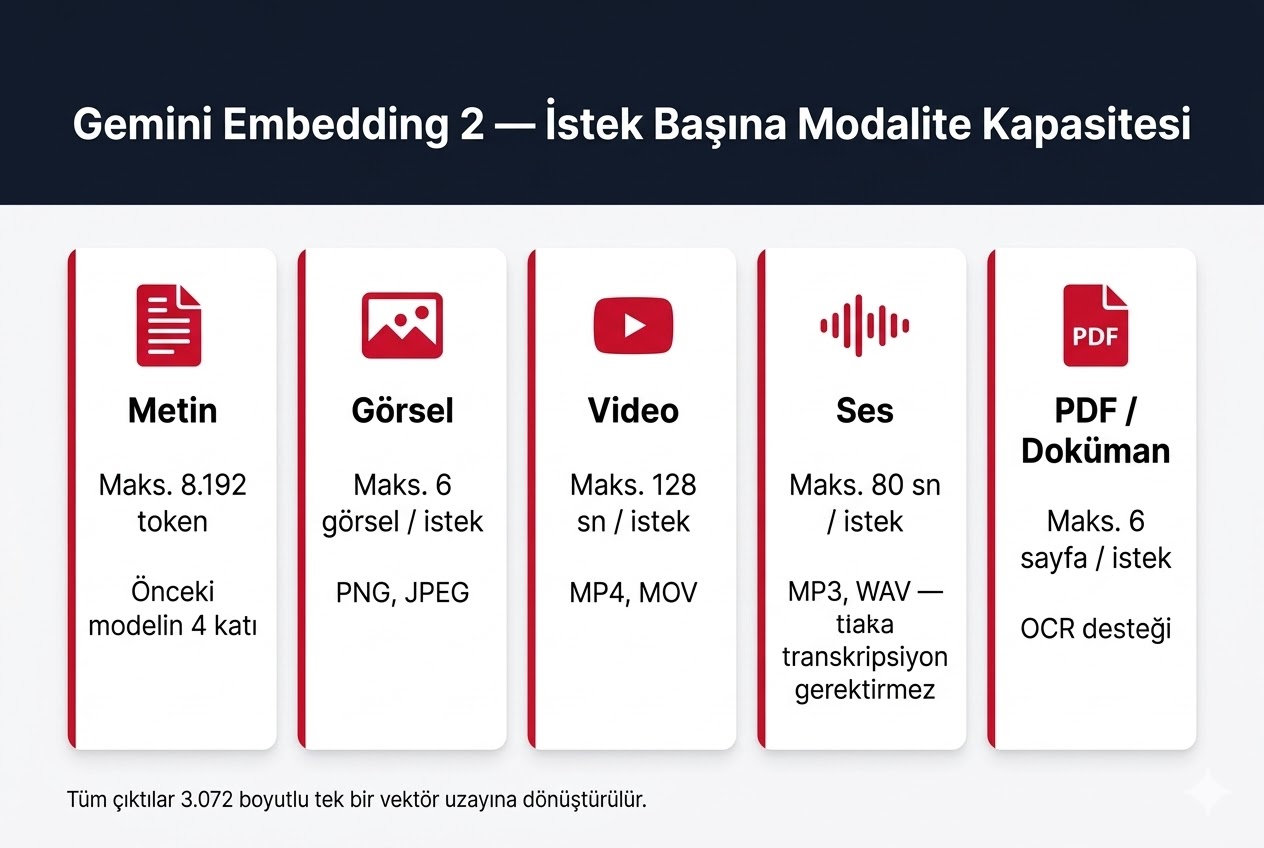
Gemini Embedding 2, metin, görsel, video, ses ve PDF verilerini tek bir 3.072 boyutlu vektör uzayına dönüştüren Google'ın ilk multimodal embedding modelidir. 100'den fazla dili destekler, Gemini mimarisi üzerine inşa edilmiştir ve Gemini API ile Vertex AI üzerinden public preview olarak kullanılabilir.
Daha önceki embedding modelleri yalnızca metinle çalışıyordu. Bir e-ticaret sitesinde ürün görsellerini, bir hukuk firmasında toplantı kayıtlarını, bir medya şirketinde video arşivini aranabilir kılmak istediğinizde her biri için ayrı bir model ve ayrı bir vektör veritabanı kurmanız gerekiyordu. Gemini Embedding 2, beş farklı veri türünü tek API çağrısında aynı vektör uzayına yerleştirerek bu fragmentasyonu sonlandırıyor. Erken erişim partnerlerinden gelen veriler, birleşik pipeline'ın bazı iş akışlarında gecikmeyi %70'e kadar azalttığını gösteriyor.
Bu rehberde modelin teknik kapasitesini, mevcut alternatiflere karşı konumunu, pratik geçiş stratejisini ve kendi iş akışınızda nasıl değerlendirebileceğinizi ele alıyoruz.
Rakiplerle Karşılaştırma: OpenAI, Cohere, Amazon Nova
Gemini Embedding 2 boşlukta çıkmadı. 2025 sonundan itibaren multimodal embedding alanı hızla kalabalıklaştı: Amazon, Aralık 2025'te Nova Multimodal Embeddings'i duyurdu; Cohere, embed-v4 ile kurumsal müşterilere yöneldi; OpenAI ise text-embedding-3 serisini geniş geliştirici tabanıyla domine etmeye devam ediyor. Karar vermek için bu modellerin neyi farklı yaptığını görmek gerekir.
| Model | Modalite | Maks. Boyut | MRL Desteği | Dil | Statü |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Metin, görsel, video, ses, PDF | 3.072 | Var (768–3.072) | 100+ | Public Preview |
| Amazon Nova Multimodal | Metin, görsel, video, ses, doküman | 3.072 | Var (256–3.072) | 200+ | GA (Bedrock) |
| Cohere embed-v4 | Metin, görsel | 1.024 | Var | 100+ | GA |
| OpenAI text-embedding-3 | Yalnızca metin | 3.072 | Var | Çoklu | GA |
* Tablo, Mart 2026 itibarıyla kamuya açık dokümantasyonlara dayanmaktadır. Fiyatlar ve özellikler değişebilir.
Tablo bağlamı olmadan eksik kalır. Bu modellerin her biri farklı bir ekosistem için optimize edilmiş — doğru seçim, hangi modelin "en iyi" olduğuna değil, mevcut altyapınıza ve ihtiyaç duyduğunuz modalite genişliğine bağlı.
Dürüst not: Gemini Embedding 2 şu an public preview statüsünde — production SLA'sı henüz yok. Ayrıca önceki model (gemini-embedding-001) ile vektör uzayları uyumsuz: mevcut veritabanınızdaki vektörleri yeni modelle karşılaştıramazsınız, tüm veriyi yeniden embed etmeniz gerekir. Preview'dan GA'ya geçişte model davranışında değişiklikler olabilir. Kritik production sistemlerinde doğrudan geçiş yerine bir sonraki bölümde anlattığımız shadow index stratejisini değerlendirin.
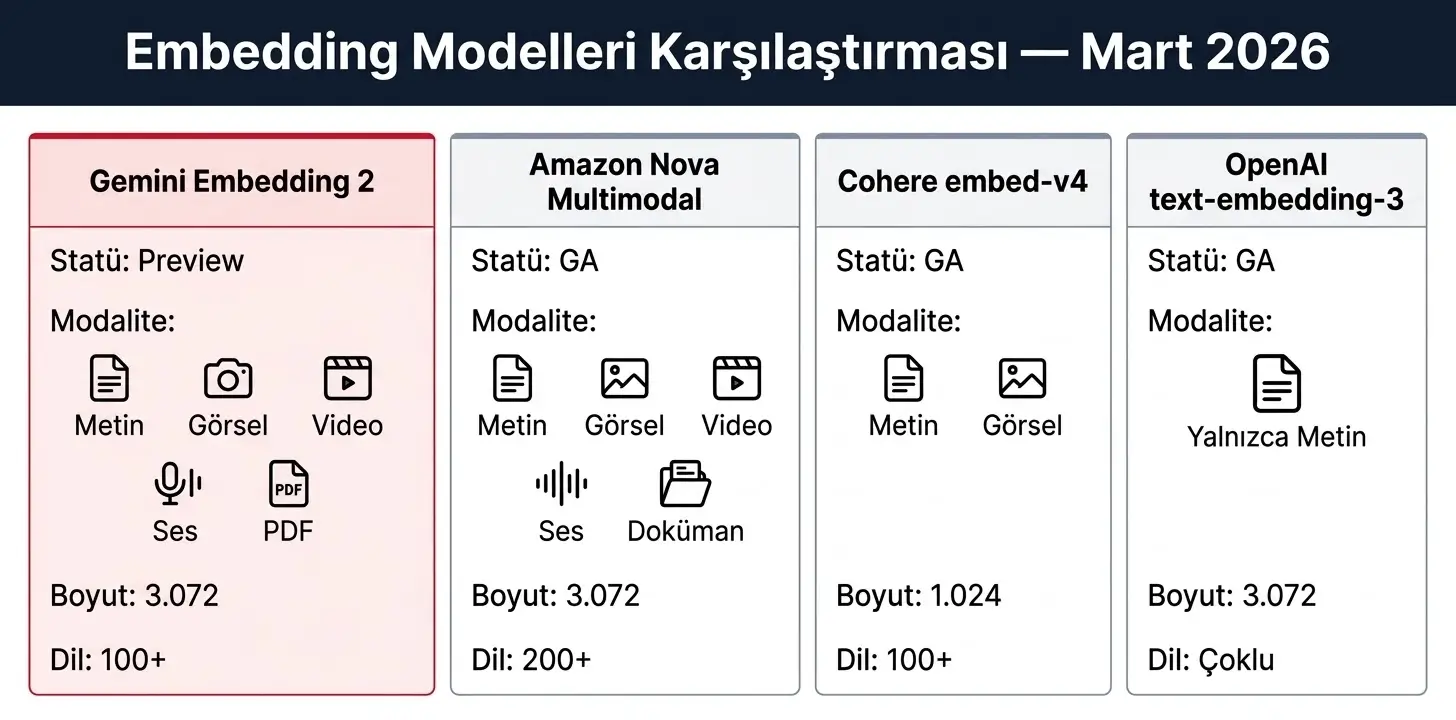
Mart 2026 itibarıyla öne çıkan embedding modellerinin modalite desteği, boyut seçenekleri ve ekosistem konumlandırması.
Kısa özet: Multimodal genişlik + Google ekosistemi → Gemini Embedding 2. AWS altyapısı + GA güvencesi → Amazon Nova. Kurumsal metin arama + maliyet optimizasyonu → Cohere. Mevcut OpenAI entegrasyonu + yalnızca metin → text-embedding-3. Hiçbiri diğerini geçersiz kılmıyor — doğru seçim, mevcut yığınınıza ve öncelikli kullanım senaryonuza bağlı.