
ChatGPT'ye bir soru sordun, güvenle cevap verdi — ama cevap yanlıştı. Ya da doğruydu, ama altı ay öncesinin verisine dayanıyordu. Bu deneyimi yaşamayan yapay zeka kullanıcısı neredeyse kalmadı.
Büyük dil modelleri (LLM) milyarlarca parametre ile eğitiliyor, dilin yapısını anlıyor, analiz yapabiliyor, cümle kurabiliyor. Ama bir sorunları var: eğitim verilerinin ötesini bilmiyorlar. Eğitim sırasında öğrendikleri her şey bir noktada donduruluyor. O noktadan sonra dünya değişmeye devam ediyor — model ise aynı kalıyor. İşte RAG, bu sorunu çözmek için ortaya çıkan mimari.
RAG (Retrieval-Augmented Generation), büyük dil modellerinin yanıt üretmeden önce dış bilgi kaynaklarını — veritabanlarını, web sayfalarını, belgeleri — tarayarak güncel ve doğrulanabilir bilgiye ulaşmasını sağlayan bir yapay zeka mimarisidir. Türkçeye "Getirme ile Güçlendirilmiş Üretim" olarak çevrilebilir.
Modelin yalnızca eğitim verisine bağlı kalması yerine, gerçek zamanlı olarak eriştiği kaynaklara dayanarak cevap üretmesini sağlar. Kısacası yapay zekaya "bilmediğin bir şey sorulduğunda önce araştır, sonra cevap ver" yeteneği kazandırır.
Kavram 2020'de Meta AI (eski adıyla Facebook AI Research) araştırmacılarının yayınladığı bir akademik makaleyle tanıtıldı. Ama RAG'in gerçek etkisi son iki yılda ortaya çıktı — Perplexity, ChatGPT ve Gemini gibi AI yanıt motorları artık web'deki içerikleri aktif olarak tarıyor, filtreliyor ve kaynak göstererek kullanıyor. Bu motorların içeriği bulma, seçme ve sunma mekanizmasının temelinde RAG var.
Eğer içerik üretiyorsan veya bir web sitesinin görünürlüğünden sorumluysan, RAG sadece "yapay zekanın teknik bir terimi" değil — içeriğinin AI sistemleri tarafından bulunup bulunmayacağını, kaynak gösterilip gösterilmeyeceğini belirleyen mekanizmanın adı.
Bu yazıda RAG'in nasıl çalıştığını, avantajlarını ve sınırlarını, AI yanıt motorlarında sitenin görünürlüğünü nasıl etkilediğini — ve bu görünürlüğü artırmak için somut olarak ne yapabileceğini anlatacağım.
RAG Nasıl Çalışır?
Bir kütüphaneye gittiğini düşün. Sorunun var, cevabı bilmiyorsun. Doğrudan kafandan bir şey uydurmak yerine önce uygun kitabı buluyorsun, ilgili sayfaları okuyorsun, sonra kendi cümlelerinle cevabı yazıyorsun. RAG'in yaptığı tam olarak bu — ama milisaniyeler içinde, milyonlarca belge arasında.
Teknik olarak RAG üç aşamadan oluşuyor. 2020'de Patrick Lewis ve ekibinin Meta AI'da yayınladığı orijinal araştırma makalesinde tanımlanan bu mimari, o günden bu yana yüzlerce farklı uygulamaya temel oluşturdu. Adımlar basit, güçlü olan şey bu adımların birlikte çalışma biçimi.
Getirme (Retrieval)
Kullanıcı bir soru soruyor. Sistem bu soruyu sayısal bir temsile — "embedding" adı verilen vektöre — dönüştürüyor. Sonra bu vektörü bir vektör veritabanında (vector database) saklanan binlerce belge vektörüyle karşılaştırarak en alakalı bilgi parçalarını buluyor. Bu süreç bir arama motorunun yaptığına benzer ama anahtar kelime eşleşmesi yerine anlam benzerliği ölçer.
Zenginleştirme (Augmentation)
Bulunan bilgi parçaları, kullanıcının orijinal sorusuyla birleştirilerek genişletilmiş bir prompt oluşturuluyor. Yani model artık sadece "kullanıcı ne sordu?" bilgisiyle değil, "bu soruya cevap verecek en güncel belgeler neler?" bilgisiyle birlikte çalışıyor. Bu adım prompt mühendisliği tekniklerini otomatikleştiriyor.
Üretim (Generation)
Dil modeli bu zenginleştirilmiş prompt'u alıyor — hem kendi eğitim bilgisini hem de getirilen belgeleri kullanarak bir yanıt üretiyor. Kritik fark şu: model artık sadece "bildiği şeylerden" değil, kendisine sunulan güncel ve spesifik kaynaklardan beslenerek cevap veriyor. Bu sayede cevap doğrulanabilir ve kaynak gösterilebilir hale geliyor.
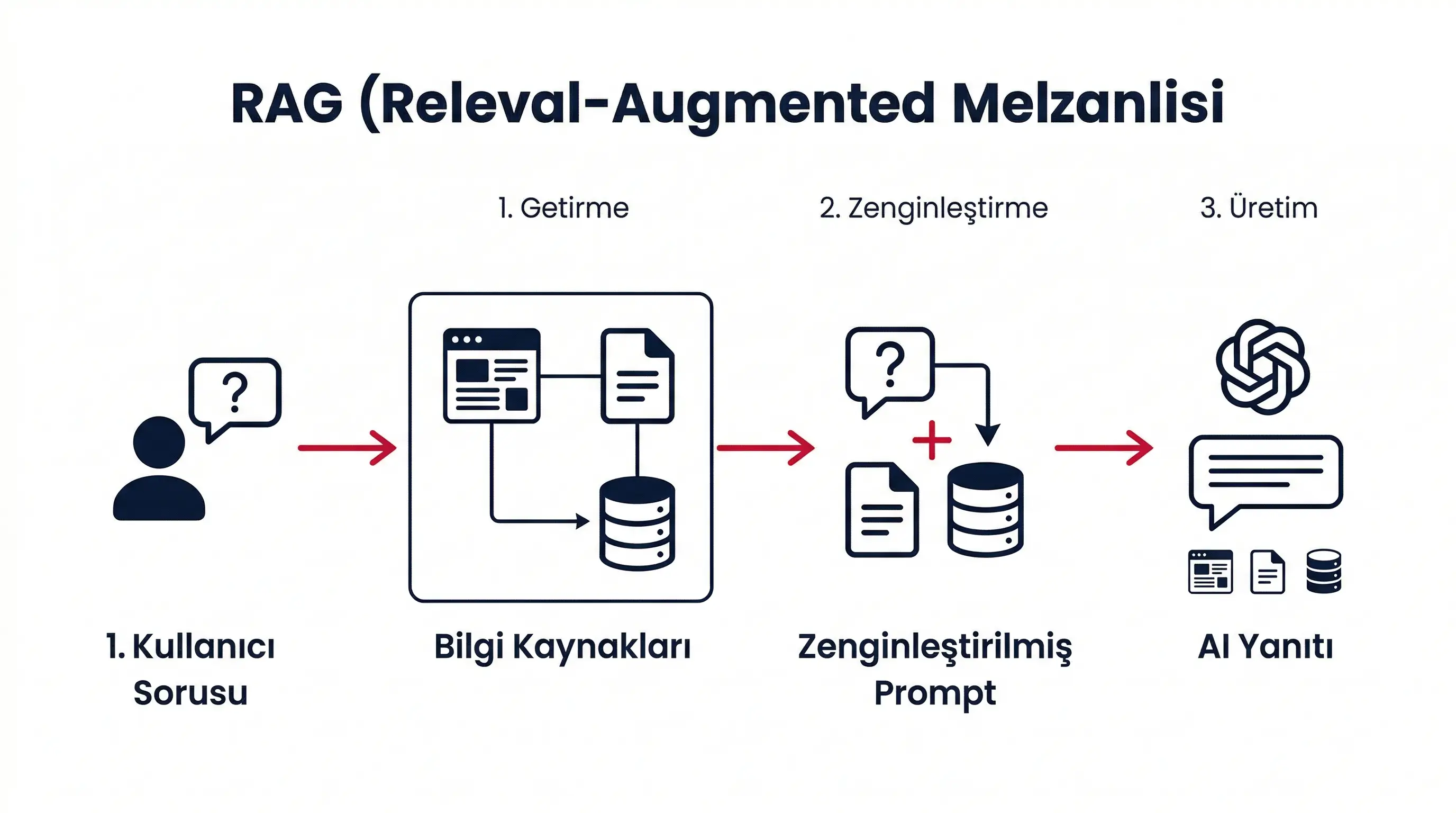
Bu üç adımın arkasındaki en kritik kavram embedding — yani metnin sayısal temsili. Bir cümle veya belge, yüzlerce boyutlu bir vektöre dönüştürülüyor ve bu vektörler arasındaki mesafe anlam benzerliğini ölçüyor. "İstanbul'da hava nasıl?" ile "İstanbul hava durumu" farklı kelimeler kullanıyor ama aynı anlama yakın — embedding modelleri bu yakınlığı yakalıyor. Bu konunun derinliklerine inmek istersen Gemini Embedding 2 yazımızda embedding modellerinin nasıl çalıştığını detaylı anlattık.
Sonuç olarak RAG, modeli yeniden eğitmeden — yani milyonlarca dolar ve haftalarca işlem gücü harcamadan — yapay zekayı güncel bilgiye bağlıyor. Bu yüzden 2024'ten itibaren neredeyse tüm büyük AI yanıt motorları — Perplexity, ChatGPT'nin web arama modu, Google Gemini — bir tür RAG mekanizması kullanıyor.
RAG Ne İşe Yarar?
Büyük dil modellerinin en yaygın eleştirisi "bazen çok güvenli bir şekilde yanlış söylüyor" oldu. Buna halüsinasyon deniyor — model, eğitim verisinde olmayan bir bilgiyi "uyduruyor" ama sanki kesin biliyormuş gibi sunuyor. RAG bu soruna doğrudan müdahale ediyor; ama tek faydası bu değil ve her şeyi çözmüyor. İkisini birden anlamak gerek.
RAG'in Güçlü Yanları
RAG'in Sınırları
RAG, SEO ve GEO: İçerik Üreticisini Neden İlgilendiriyor?
Buraya kadar RAG'in ne olduğunu ve nasıl çalıştığını anlattık. Ama asıl soru şu: eğer bir web sitesi yönetiyorsan, içerik üretiyorsan veya SEO yapıyorsan — RAG seni neden ilgilendiriyor?
Çünkü Perplexity, ChatGPT, Gemini gibi AI yanıt motorları artık sadece kendi eğitim verisiyle cevap üretmiyor. Bu motorlar web'i aktif olarak tarıyor, içerikleri indeksliyor, en güvenilir buldukları kaynakları seçip cevaplarına entegre ediyor — ve bazıları kaynak linki veriyor. Bu sürecin teknik adı RAG. Yani senin sitenin AI sistemleri tarafından "güvenilir kaynak" olarak seçilip seçilmemesi, doğrudan RAG mekanizmasının nasıl çalıştığıyla ilgili.
Klasik SEO'da hedef Google'ın ilk sayfasıydı. Şimdi bir katman daha eklendi: AI yanıt motorlarının kaynak havuzuna girmek. Bu yeni katmana GEO (Generative Engine Optimization) deniyor — ve RAG bu katmanın altyapısı.
AI'ın Kaynak Havuzuna Girmek İçin Ne Yapmalısın?
RAG sistemleri kaynak seçerken rastgele davranmıyor. Bir sayfanın "güvenilir kaynak" olarak seçilme olasılığını artıran somut yapısal faktörler var. Bunların çoğu zaten iyi SEO pratiğiyle örtüşüyor — ama bazıları klasik SEO'nun ötesinde.
FAQPage, Article, HowTo gibi schema türleri içeriğinin ne hakkında olduğunu makine düzeyinde tanımlıyor. AI sistemleri bu yapıyı okuyarak hangi sayfanın hangi soruya cevap verdiğini daha kolay eşleştiriyor.
Her konunun giriş paragrafında, bağlamdan bağımsız olarak anlaşılabilir bir tanım cümlesi bulunması. RAG sistemleri bilgi parçaları (chunk) halinde çalıştığı için, cümlen tek başına okunduğunda da anlam taşımalı.
Sitenin kök dizinine eklenen bu dosya, AI tarayıcılarına sitenin yapısını ve en önemli sayfalarını özetliyor. robots.txt nasıl arama motorları için bir yol haritası ise, llms.txt de AI sistemleri için benzer bir işlev görüyor.
H1-H2-H3 yapısı sadece Google için değil, AI sistemlerinin içeriğini anlamlandırması için de kritik. Canonical URL'lerin tutarlı olması, AI'ın aynı içeriği farklı kaynaklardan çekip çelişkili bilgi üretmesini engelliyor.
Bu adımların çoğu tanıdık gelmiş olabilir — çünkü iyi SEO ile iyi GEO pratiği büyük ölçüde örtüşüyor. Fark, bakış açısında: artık sadece "Google botu bu sayfayı nasıl okuyor?" değil, "bir AI modeli bu sayfadan bilgi parçası çektiğinde ne anlıyor?" sorusunu da sorman gerekiyor. llms.txt dosyasının nasıl oluşturulacağını ve GEO stratejisinin detaylarını llms.txt rehberimizde adım adım anlattık.
AI Motorlarının Sitenden Bilgi Çektiğini Nasıl Anlarsın?
Server log analizi: Perplexity, ChatGPT ve diğer AI botları sitenizi tararken kendilerini tanımlayan user-agent bilgileri bırakıyor. Server log'larında "PerplexityBot", "ChatGPT-User", "GPTBot", "ClaudeBot" gibi user-agent'ları filtrelemek, hangi sayfalarınızın AI tarafından ne sıklıkla tarandığını gösterir.
Referrer trafik: Google Analytics 4 veya benzeri analitik araçlarında kaynak/ortam (source/medium) raporlarını kontrol et. "perplexity.ai / referral" veya benzeri girişler, AI motorlarından gelen doğrudan tıklamaları gösteriyor. Bu trafik henüz küçük olabilir ama trendi izlemek önemli.
Manuel doğrulama: Perplexity'de kendi alanınla ilgili birkaç soru sor. Cevabın altındaki kaynak listesinde sitenin görünüp görünmediğini kontrol et. Bu en basit ama en somut testtir.
Bu ölçüm pratikleri henüz standart bir dashboard'a oturmadı — sektörde herkes aynı şeyi farklı yöntemlerle takip ediyor. Ama trendi izlemek, AI trafik kanalının büyüyüp büyümediğini anlamak için şimdiden bu verileri toplamaya başlamak gerekiyor.
RAG Hakkında Sıkça Sorulan Sorular
RAG nasıl çalışır?
RAG üç adımda çalışır: önce kullanıcının sorusu alınır ve bir bilgi kaynağında (veritabanı, web sayfaları, belgeler) bu soruyla en alakalı bilgi parçaları bulunur (getirme). Sonra bulunan bilgiler soruyla birleştirilerek zenginleştirilmiş bir prompt oluşturulur (zenginleştirme). Son adımda dil modeli bu genişletilmiş prompt'u kullanarak güncel ve kaynağa dayalı bir yanıt üretir (üretim).
RAG ile fine-tuning arasındaki fark nedir?
RAG, modelin kendisine dokunmadan dış kaynaklardan bilgi çekerek yanıt kalitesini artırır — bilgi güncellemesi için idealdir. Fine-tuning ise modelin ağırlıklarını özel bir veri setiyle yeniden eğiterek değiştirir — belirli bir ton, stil veya davranış kalıbı kazandırmak için kullanılır. 2026'da üretim ortamlarındaki yaygın yaklaşım ikisini birlikte kullanmak: değişen bilgiyi RAG'e, sabit davranışı fine-tuning'e vermek.
RAG ne işe yarar?
RAG, büyük dil modellerinin yeniden eğitim gerektirmeden güncel, doğrulanabilir ve alana özgü bilgiye dayanarak cevap üretmesini sağlar. Halüsinasyonu azaltır, cevaplara kaynak gösterilebilirlik kazandırır ve bilgi kaynağı güncellendikçe modelin çıktıları da otomatik olarak güncellenir. Müşteri hizmetleri chatbot'larından kurumsal bilgi tabanlarına, araştırma asistanlarından AI arama motorlarına kadar geniş bir uygulama alanı vardır.
RAG SEO'yu bitirir mi?
Hayır, ama dönüştürüyor. RAG kullanan AI yanıt motorları web'deki içerikleri tarayıp kaynak olarak kullandıkça, klasik anahtar kelime optimizasyonunun yanına yeni bir katman ekleniyor: yapılandırılmış veri (schema markup), net tanım cümleleri ve AI tarayıcılarına uyumlu site mimarisi. SEO ölmüyor — kapsamı genişliyor. Artık sadece Google'da değil, AI yanıt motorlarında da görünür olmak gerekiyor. Bu yeni katmana GEO (Generative Engine Optimization) deniyor.
RAG halüsinasyonu tamamen önler mi?
Hayır. RAG, modeli dış kaynaklara dayandırarak halüsinasyonu ciddi oranda azaltır ama tamamen ortadan kaldırmaz. Model, doğru kaynak getirilmiş olsa bile bağlamı yanlış yorumlayabilir veya kaynakta olmayan çıkarımlar yapabilir. Özellikle kritik kararlarda — tıbbi, hukuki veya finansal bilgilerde — RAG çıktısını her zaman insan gözüyle doğrulamak gerekir.
RAG web siteme trafik kaybettirir mi?
Risk var ama tek yönlü değil. AI yanıt motorları kullanıcının sorusunu doğrudan cevaplayabildiği için bazı aramalar "sıfır tıklamayla" sonuçlanabiliyor — kullanıcı siteye hiç gelmeden cevabı alıyor. Ama diğer taraftan, AI'ın seni kaynak göstermesi yeni bir trafik ve güvenilirlik kanalı açıyor. Riskin büyüklüğü sektöre ve içerik türüne göre değişiyor; önemli olan bu kanalı ölçmeye başlamak ve içeriğini her iki dünya için optimize etmek.
AI motorlarının sitemden bilgi çektiğini nasıl anlarım?
Üç pratik yöntem var: birincisi, server log'larında "PerplexityBot", "GPTBot", "ClaudeBot" gibi AI bot user-agent'larını filtreleyerek hangi sayfalarının ne sıklıkla tarandığını görmek. İkincisi, Google Analytics 4'te kaynak raporlarında "perplexity.ai / referral" gibi girişleri izlemek. Üçüncüsü ve en basiti, Perplexity veya ChatGPT'de kendi alanınla ilgili sorular sorup cevabın altındaki kaynak listesinde sitenin görünüp görünmediğini kontrol etmek.
RAG Hakkında Sıkça Sorulan Sorular
RAG nasıl çalışır?
RAG üç adımda çalışır: önce kullanıcının sorusu alınır ve bir bilgi kaynağında (veritabanı, web sayfaları, belgeler) bu soruyla en alakalı bilgi parçaları bulunur (getirme). Sonra bulunan bilgiler soruyla birleştirilerek zenginleştirilmiş bir prompt oluşturulur (zenginleştirme). Son adımda dil modeli bu genişletilmiş prompt'u kullanarak güncel ve kaynağa dayalı bir yanıt üretir (üretim).
RAG ile fine-tuning arasındaki fark nedir?
RAG, modelin kendisine dokunmadan dış kaynaklardan bilgi çekerek yanıt kalitesini artırır — bilgi güncellemesi için idealdir. Fine-tuning ise modelin ağırlıklarını özel bir veri setiyle yeniden eğiterek değiştirir — belirli bir ton, stil veya davranış kalıbı kazandırmak için kullanılır. 2026'da üretim ortamlarındaki yaygın yaklaşım ikisini birlikte kullanmak: değişen bilgiyi RAG'e, sabit davranışı fine-tuning'e vermek.
RAG ne işe yarar?
RAG, büyük dil modellerinin yeniden eğitim gerektirmeden güncel, doğrulanabilir ve alana özgü bilgiye dayanarak cevap üretmesini sağlar. Halüsinasyonu azaltır, cevaplara kaynak gösterilebilirlik kazandırır ve bilgi kaynağı güncellendikçe modelin çıktıları da otomatik olarak güncellenir. Müşteri hizmetleri chatbot'larından kurumsal bilgi tabanlarına, araştırma asistanlarından AI arama motorlarına kadar geniş bir uygulama alanı vardır.
RAG SEO'yu bitirir mi?
Hayır, ama dönüştürüyor. RAG kullanan AI yanıt motorları web'deki içerikleri tarayıp kaynak olarak kullandıkça, klasik anahtar kelime optimizasyonunun yanına yeni bir katman ekleniyor: yapılandırılmış veri (schema markup), net tanım cümleleri ve AI tarayıcılarına uyumlu site mimarisi. SEO ölmüyor — kapsamı genişliyor. Artık sadece Google'da değil, AI yanıt motorlarında da görünür olmak gerekiyor. Bu yeni katmana GEO (Generative Engine Optimization) deniyor.
RAG halüsinasyonu tamamen önler mi?
Hayır. RAG, modeli dış kaynaklara dayandırarak halüsinasyonu ciddi oranda azaltır ama tamamen ortadan kaldırmaz. Model, doğru kaynak getirilmiş olsa bile bağlamı yanlış yorumlayabilir veya kaynakta olmayan çıkarımlar yapabilir. Özellikle kritik kararlarda — tıbbi, hukuki veya finansal bilgilerde — RAG çıktısını her zaman insan gözüyle doğrulamak gerekir.
RAG web siteme trafik kaybettirir mi?
Risk var ama tek yönlü değil. AI yanıt motorları kullanıcının sorusunu doğrudan cevaplayabildiği için bazı aramalar "sıfır tıklamayla" sonuçlanabiliyor — kullanıcı siteye hiç gelmeden cevabı alıyor. Ama diğer taraftan, AI'ın seni kaynak göstermesi yeni bir trafik ve güvenilirlik kanalı açıyor. Riskin büyüklüğü sektöre ve içerik türüne göre değişiyor; önemli olan bu kanalı ölçmeye başlamak ve içeriğini her iki dünya için optimize etmek.
AI motorlarının sitemden bilgi çektiğini nasıl anlarım?
Üç pratik yöntem var: birincisi, server log'larında "PerplexityBot", "GPTBot", "ClaudeBot" gibi AI bot user-agent'larını filtreleyerek hangi sayfalarının ne sıklıkla tarandığını görmek. İkincisi, Google Analytics 4'te kaynak raporlarında "perplexity.ai / referral" gibi girişleri izlemek. Üçüncüsü ve en basiti, Perplexity veya ChatGPT'de kendi alanınla ilgili sorular sorup cevabın altındaki kaynak listesinde sitenin görünüp görünmediğini kontrol etmek.
Sonuç: RAG Sadece Teknik Bir Terim Değil, Görünürlük Meselesi
RAG, yapay zekanın "bilmediği konularda bile cevap uyduran sistem"den "önce araştırıp sonra konuşan sistem"e dönüşmesini sağlayan mimari. Kavram 2020'de akademik bir makalede doğdu ama etkisi 2026'da herkesin günlük hayatına girdi — Perplexity'ye sorduğun bir sorunun altındaki kaynak listesinden, ChatGPT'nin web'i tarayarak verdiği cevaba kadar.
Eğer içerik üretiyorsan, bu seni iki şekilde etkiliyor. Birincisi: yapılandırılmış, net ve güvenilir içerik üretirsen AI sistemleri seni kaynak olarak seçiyor — yeni bir görünürlük kanalı açılıyor. İkincisi: bu kanalı görmezden gelirsen, rakiplerin bu alanda senden önce konumlanıyor.
Bu yazıda anlattıklarımız başlangıç noktası. AI ekosistemi hızla değişiyor — embedding modelleri, GEO stratejileri ve yapay zeka araçlarının pratik kullanımı hakkında derinleşmek istersen bu yazıları da incele:
Claude Code Nedir? — Yapay zeka destekli geliştirme aracının 2026 güncel rehberi
Web sitenizin AI yanıt motorlarındaki görünürlüğünü artırmak, GEO stratejinizi kurmak veya teknik SEO altyapınızı güçlendirmek mi istiyorsunuz?
Dijital varlığınızı hem Google hem de AI ekosistemi için optimize ediyorum.

